1、首先,分析网页,网站的URL都很有规律,没个美女的套图是这样http://www.mmjpg.com/mm/1336 ,从1到1336,每张大图的地址是在id为"content"的div标签里面,如图:
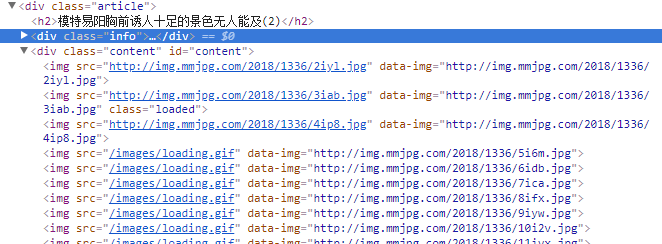
2、然后爬取的思路就很清晰了,从1到1336,依次获取并打开每一份套图的地址,接着点击所有图片的元素链接,加载出所有图片的地址,再根据获得的图片地址写入到本地文件中。
这里有个需要注意的地方,当程序不加任何headers直接打开图片地址时,会跳转到同一页面,所以放弃了urllib.request.urlretrieve来下载图片,因为我还没找到怎么在里面加head头信息的方法,跳转的地址如下图:

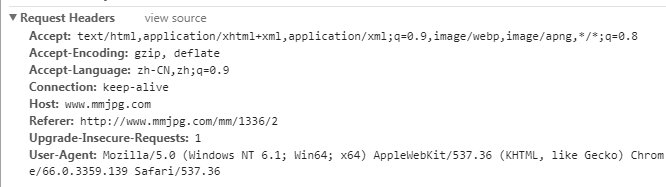
3、这时只要加上head头信息就可以解决了,其中关键值是referer,只要是本地域名下都可以,告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。
4、代码如下:用了比较简单的代码。
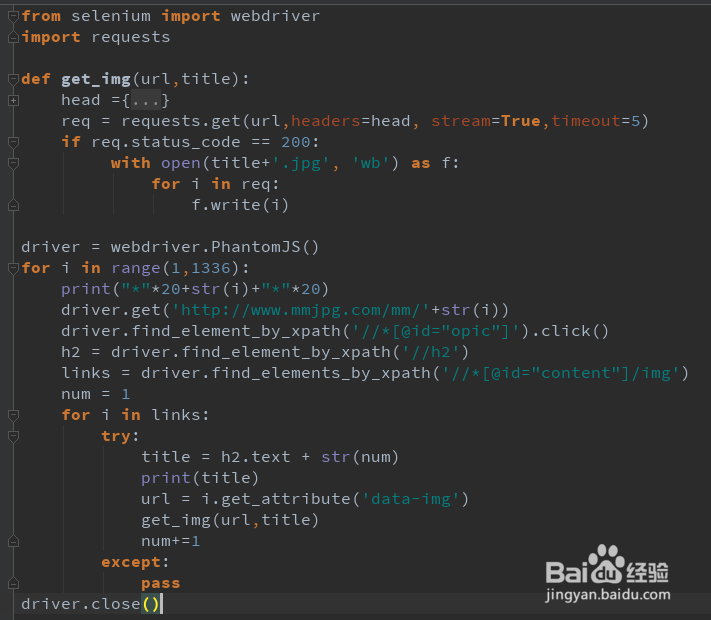
1、代码首先用requests造了一个用来下载图片的函数,传入下载地址和图片文件名为参数,以备获取到图片地址后直接使用,然后使用selenium依次打开从1到1336份套图,定位“全部图片”元素,进行点击。
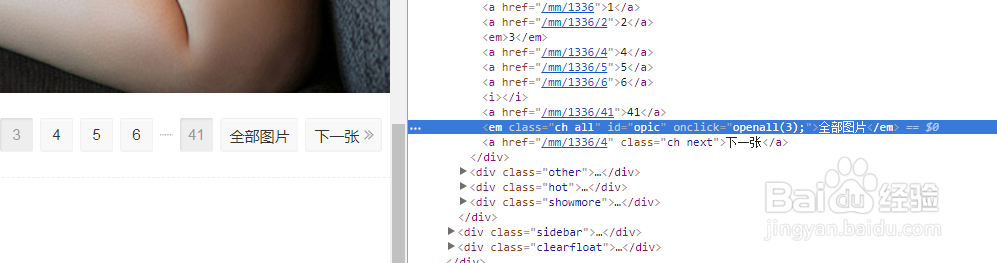
2、也可以直接用driver.find_element_by_id('opic')来定位,那样会更加简单准确,不过经常练习使用xpath来定位也是很有益处的,.click()点击元素后,重新打印源码就会加载出所有图片的信息了,如图一所示,接着定位获取标题,加入递增标量后用来当做文件的名称,就不用管每一份套图具体有多少张图片了,继续定位图片链接,并获取href属性,来作为下载函数的参数,在每个套图循环中运行函数完成图片下载。
经过一段时间,大概一个多小时吧,图片下载成果如下: