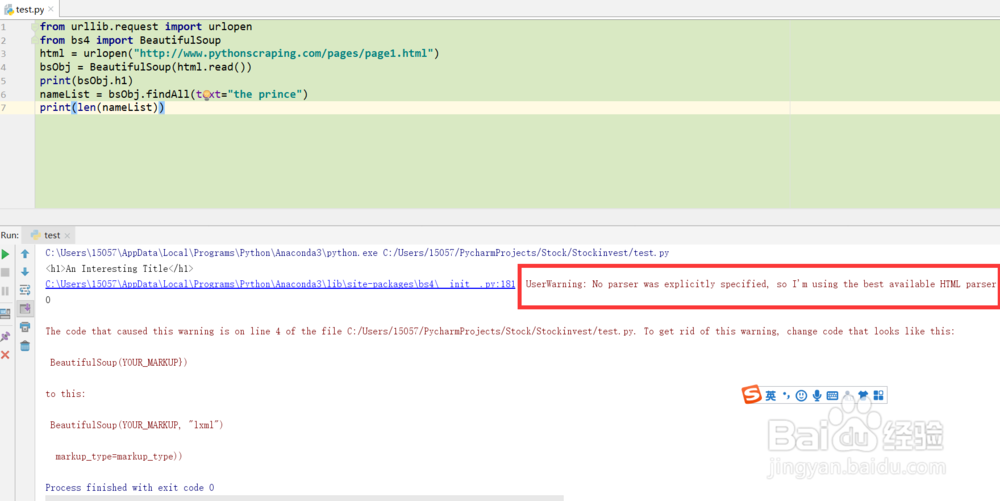
1、Python在进行网页爬虫时,代码如下:from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen("http://www.pythonscraping.com/pages/page1.html") bsObj = BeautifulSoup(html) print (bsObj.h1) nameList = bsObj.findAll(text='the prince') print(len(nameList))

2、在运行代码时出现了一个用户警告,如下:UserWarning: No parser was explicitly specified, so I'm us足毂忍珩ing the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.0

3、紧接着是因此此警告的原因,初始化时,未加上解析器亿姣灵秀类型The code that caused this warning is on line 4 of the file C:/Users/15057/PycharmProjects/Stock/Stockinvest/test.py. To get rid of this warning, change code that looks like this:BeautifulSoup(YOUR_MARKUP})to this:BeautifulSoup(YOUR_MARKUP, "lxml") markup_type=markup_type)

4、详细情况如图所示:
5、将代码bsObj = BeautifulSoup(html.read())改为bsObj = BeautifulSoup(html.read(),"lxml")就不会报错了

