1、第一步,在任意浏览器页面右击,找到审查元素,或者是查看网页源代码。一般情况下,不同的浏览器有不同的进入方式,还有一个更快捷的方式:按F12直接进入HTML后台。

2、第二步,进入到开发者工具中,进入后首先看到的是HTML代码,我们点击图中的Network,进入到网络请求信息中心。
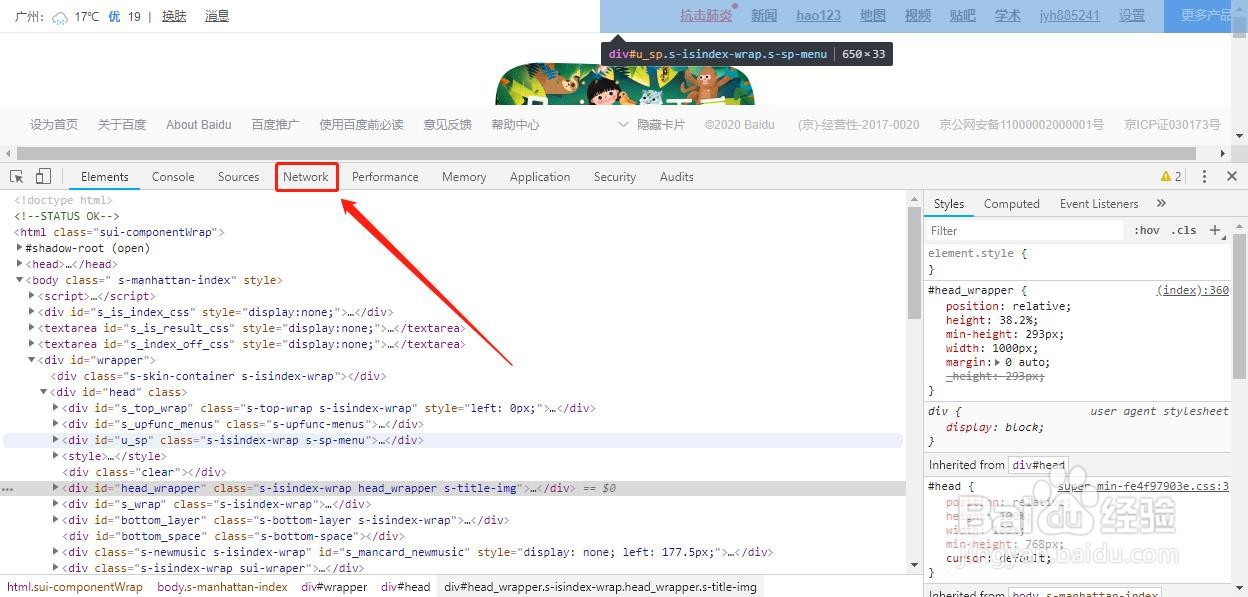
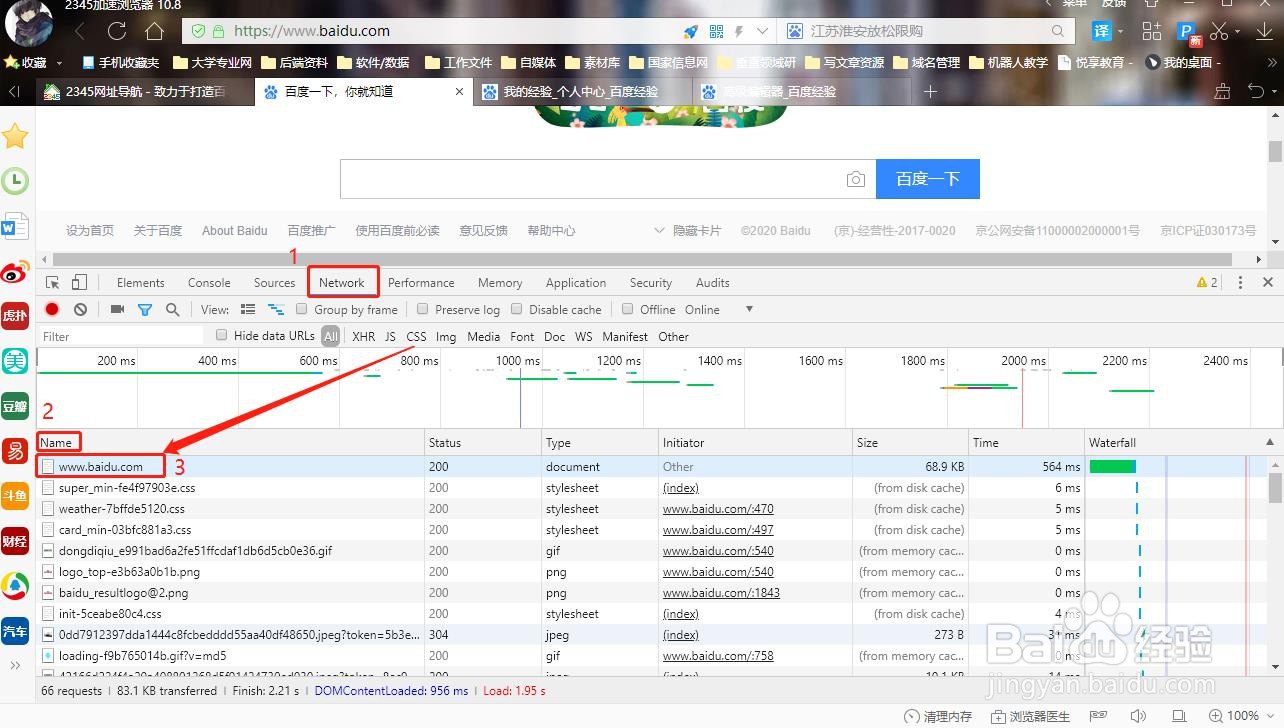
3、第三步,找到Name中的网址信息。
注意,进入的网页网址不同,查找的内容也不同,请查找自己的网址并点击。
4、第四步,点击网址之后,会出现Headers和Cookie等信息,我们找到Headers中的请求头Request Headers。因为user-agent是在HTTP请求当中发送到服务器的。

5、第五步,找到User-Agent,这里的内容包含的就是我们使用的浏览器类型、操作系统及版本、CPU 类型、浏览器渲染引擎、浏览器语言、浏览器插件等信息,然后将此信息复制粘贴到我们爬虫的代码中即可。

