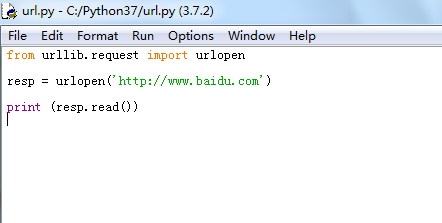
1、打开Python开发工具IDLE,新建‘url.py’文件,编写代码如下:
from urllib.request import urlopen
resp = urlopen('http://www.baidu.com')
print (resp.read())
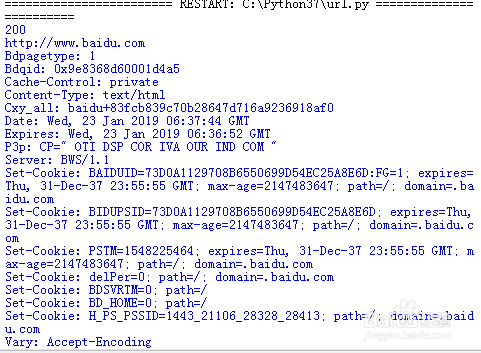
2、F5运行程序,获取到百度的首页的页面,打印源代码到Shell

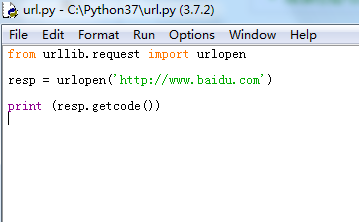
3、改写代码,打印百度返回状态码
from urllib.request import urlopen
resp = urlopen('http://www.baidu.com')
print (resp.getcode())
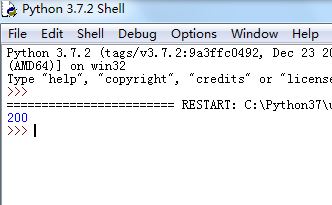
4、F5运行程序,打印出请求返回状态码200
200 代表正常
500 服务器出错
400 请求参数异常
5、改写代码,打印请求url地址
from urllib.request import urlopen
resp = urlopen('http://www.baidu.com')
print (resp.getcode())
print (resp.geturl())
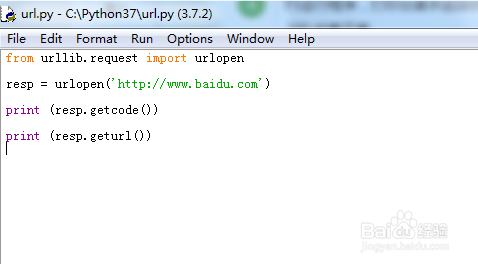
6、F5运行程序,打印出发起访问百度url

7、改写代码,打印返回头部信息
from urllib.request import urlopen
resp = urlopen('http://www.baidu.com')
print (resp.getcode())
print (resp.geturl())
print (resp.info())
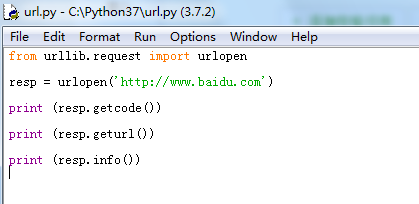
8、F5运行程序,打印出返回头部信息